

Engineering a Node.js Web Scraper
In this comprehnsive guide entitled “Engineering a Node.js Web Scraper”, you will learn how to construct a web scraper that evaluates website performance on Google using Node.js. We’ll walk you through the process of creating a basic client-server architecture, integrating web scraping capabilities, and analyzing SEO metrics. It’s crucial to undertake web scraping ethically, adhering to the guidelines specified in the target website’s robots.txt and terms of service.
Prerequisites:
- Installation of Node.js on your computer. See https://nodejs.org/en/download and https://nodejs.org/docs/latest/api
- A foundational understanding of JavaScript and Node.js. See related project, which provides a great of insight into node.js: https://docengines.com/ocr/full-stack-ocr-web-application-using-node-js-and-react/
- Acquaintance with Express.js, a Node.js web application framework. For more information on Express.js, see https://expressjs.com
Step 1: Project Initialization
Create and Navigate to Your Project Directory:
mkdir node-web-scraper
cd node-web-scraperStart a New Node.js Project:
npm init -yInstall Necessary Packages:
expressfor server setupaxiosfor HTTP requestscheeriofor HTML parsingpuppeteerfor JavaScript execution in scraping
npm install express axios cheerio puppeteer corsStep 2: Server Configuration
File Creation:
- Windows: Create
server.js - Linux: Use
touch server.js
Initialize Express Server in server.js:
const express = require('express');
const app = express();
const PORT = 3000;
app.use(express.json());
app.get('/', (req, res) => {
res.send('Web Scraper Home');
});
app.listen(PORT, () => {
console.log(`Server running on http://localhost:${PORT}`);
});Launch Your Server:
node server.jsAccess http://localhost:3000 to view the home message.
Step 3: Scraper Implementation
- Enhance
server.jswith a Scraping Endpoint: Incorporate necessary libraries and set up an endpoint to process scraping requests. Utilizeaxiosfor fetching data,cheeriofor parsing, andpuppeteerfor handling dynamic content. - Client-Side Setup:
- Create a
publicdirectory and within it, anindex.htmlfile for the user interface. - Implement a form in
index.htmlfor URL submission and display scraping results.
Running the Application:
- Navigate to your project directory and start the server with
node server.js. - Visit http://localhost:3000 in your browser to access the form.
Add a new endpoint to server.js for scraping (i.e., update the server.js file as follows:
const express = require('express');
const axios = require('axios');
const cheerio = require('cheerio');
const puppeteer = require('puppeteer');
const app = express();
const PORT = 3000;
app.use(express.json());
app.use(express.static('public')); // Serve static files from 'public' directory
app.get('/', (req, res) => {
res.sendFile(__dirname + '/public/index.html');
});
app.post('/scrape', async (req, res) => {
const { url } = req.body;
try {
const response = await axios.get(url);
const $ = cheerio.load(response.data);
const title = $('title').text();
const metaDescription = $('meta[name="description"]').attr('content');
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
const screenshotPath = `screenshot-${Date.now()}.png`;
await page.screenshot({ path: `public/${screenshotPath}` });
await browser.close();
res.json({
message: 'Scraping completed',
data: {
title,
metaDescription,
screenshotPath
}
});
} catch (error) {
console.error('Scraping error:', error);
res.status(500).json({ message: 'Error scraping the website' });
}
});
app.listen(PORT, () => {
console.log(`Server running on http://localhost:${PORT}`);
});Simple Client-Side Code
Create a folder named public in your project directory, and inside this folder, create an index.html file. This file will act as a simple client interface for sending URLs to your server for scraping.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Node Web Scraper</title>
</head>
<body>
<h1>Node.js Web Scraper</h1>
<form id="scrapeForm">
<input type="text" id="url" placeholder="Enter URL to scrape" required>
<button type="submit">Scrape</button>
</form>
<div id="result"></div>
<script>
document.getElementById('scrapeForm').onsubmit = async (e) => {
e.preventDefault();
const url = document.getElementById('url').value;
const response = await fetch('/scrape', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ url }),
});
const data = await response.json();
if (data.message === 'Scraping completed') {
document.getElementById('result').innerHTML = `
<h2>Results:</h2>
<p>Title: ${data.data.title}</p>
<p>Meta Description: ${data.data.metaDescription}</p>
<img src="${data.data.screenshotPath}" alt="Screenshot" style="max-width: 100%;">
`;
} else {
document.getElementById('result').textContent = 'Scraping failed. See console for details.';
}
};
</script>
</body>
</html>Running Your Application
In Windows, navigate to the project folder, something like this…you basically want to “cd” to your folder where your project resides:
cd C:\src\[YOUR PROJECT]Start your server by running:
node server.jsOpen your browser and go to http://localhost:3000. You’ll see a simple form to input a URL.
http://localhost:3000/index.html
Enter a URL you want to scrape and click “Scrape”. The results will be displayed below the form.
This setup demonstrates a full round-trip: the client sends a request to the server, the server processes and scrapes the website, and the client displays the results. Remember to respect websites’ robots.txt files and terms of service when scraping.
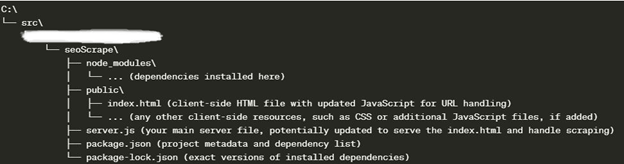
Below is what your folder structure should look like. Use this in case you end up with errors because certain files are in the wrong place, etc.:
Contact
If you’re looking to harness the power of IT to drive your business forward, Rami Jaloudi is the expert to contact. Jaloudi’s blend of passion and experience in technology makes him an invaluable resource for any organization aiming to optimize their IT strategies for maximum impact. If you want to learn more about engineering a Node.js Web Scraper or possibly adding more features, feel free to reach for assistance. Jaloudi is available on WhatsApp: https://wa.me/12018325000.




More Stories
Implementing Site-to-Site Double VPN for Enhanced Security: A Comprehensive Guide
GIMP & Digital Art – Open Source your Arts, the Sky is the Limit
Demystifying HAR Files: Creation, Collection, and Analysis for Web Application Triage
Exploring the Flipper Zero: The Multi-Tool for Modern Hackers
Comprehensive Network Diagnostics with Batch Scripting